| description |
|---|
Getting started with custom data training. |
Lucidtech offers APIs for document data extracting. The core technology is a general machine learning architecture which can be used to interpret a wide range of document types, including invoices, receipts, ID-documents, purchase orders or virtually any other type of document.
To make sure that our API provides optimal accuracy we train our models on your data. We use supervised learning for training our machine learning models. This means that the algorithms learn by observing thousands of examples of documents together with their ground truth. The goal of the training process is that Lucidtech's models learn to produce the correct output for new and previously unseen documents.
The amount of data needed to create a high quality model depends on the expected variation of the data as well as the quality of the training data. As a general rule of thumb we require at least 10 000 documents when training a new model, but 30 000+ documents is recommended for an optimal result. When the API is deployed in production, the feedback endpoints should be used to enable continuous training on new data.
The training data should be representative for the expected data. For example, if the expected data consists of invoices from thousands of different vendors, then the training data should not only consist of invoices from five different vendors.
{% hint style="success" %} A good way to select representative training data can be to choose data randomly from your database or document archive. {% endhint %}
Incorrect or missing ground truth information can be detrimental to the training process. For this reason it is important that the training data is as accurate as possible.
Ground truth data should adhere to a common format. For example, when extracting dates, all ground truth dates should be listed on the same date format regardless of how the date appears in the document. Examples of inconsistencies:
- The same date is written as 17.05.18 in one ground truth file and as 17th of May, 2018 in another.
- Different conventions are used to denote amounts, e.g. 1200.00, 1,200.00 and 1200.
{% hint style="info" %} Consistency is only required in the ground truth data. The corresponding information as written on the actual documents in the data set may be on arbitrary formats. {% endhint %}
The first step is to decide which data fields you want to extract from your documents. For an invoice this can be total amount, due date and bank account, or it can also be only total amount. For an ID document it can be first name, last name, id-number and nationality. For a travel ticket it can be price, departure date, arrival date, seat number and mean of transportation. Which data fields you want to extract is up to you to decide. We generally recommend to keep it as simple as possible. In particular, avoid adding fields that you will not use, and make sure that the majority of the data you provide contain the fields you specify.
To start training your custom model you need pairs of documents and their corresponding ground truth. The ground truth is the information you want to extract from the document. Note that every single document needs its own ground truth file.
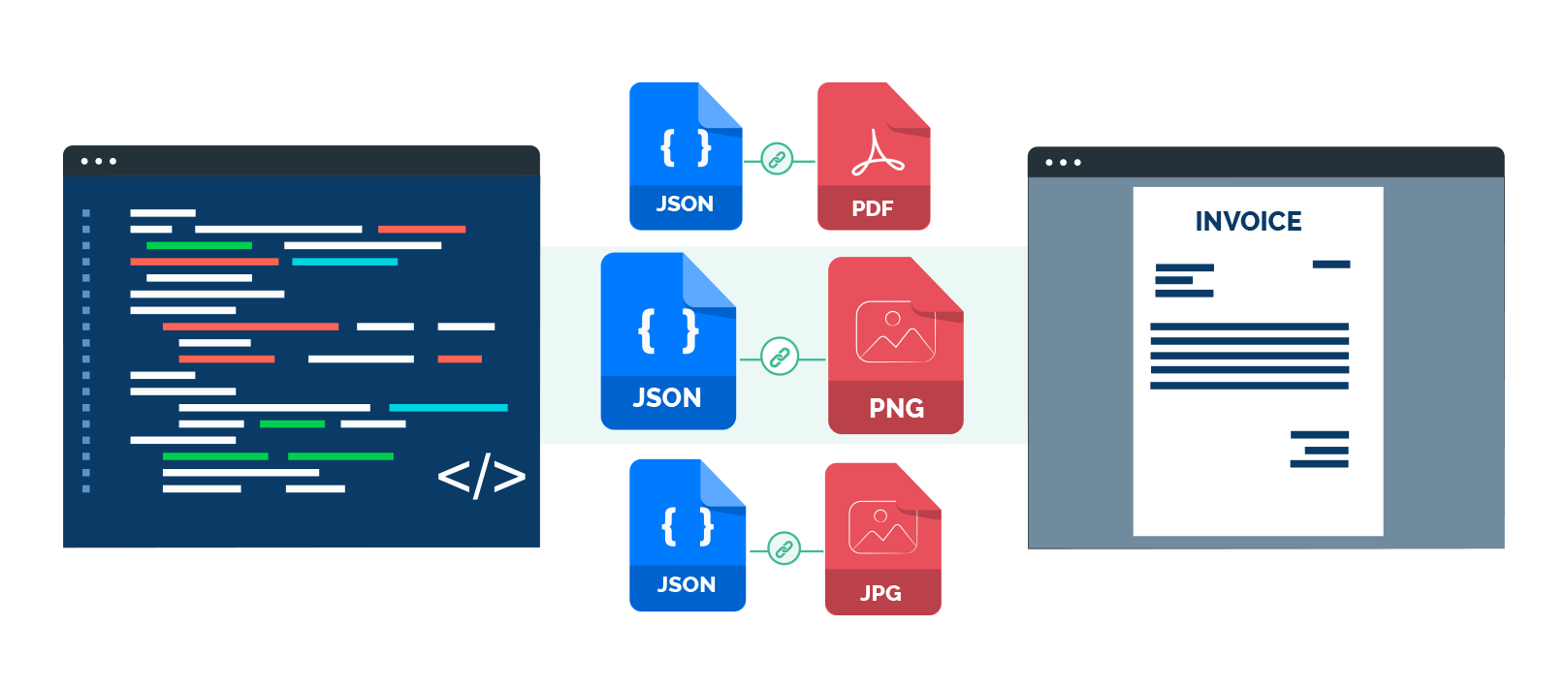
Ground truth data should be provided in JSON format according to the following specification:
{
"document": {
"path": "<path/to/document.jpg>",
"type": "<document type>"
},
"labels":{
"<your_first_field_name>": "<ground_truth_value_for_this_documents_first_field>",
"<your_second_field_name>": "<ground_truth_value_for_this_documents_second_field>",
"<your_third_field_name>": "<ground_truth_value_for_this_documents_third_field>"
}
}Examples of documents with corresponding ground truth data:
{% tabs %}
{% tab title="lucidcab.jpg" %}
 {% endtab %}
{% endtab %}
{% tab title="lucidcab.json" %}
{
"document": {
"path": "lucidcab.jpg",
"type": "receipt"
},
"labels": {
"category": "taxi",
"currency": "EUR",
"date": "2019-12-31",
"total_amount": "43.90"
}
}{% endtab %}
{% tab title="bill_of_lading.pdf " %}
 {% endtab %}
{% endtab %}
{% tab title="bill_of_lading.json" %}
{
"document": {
"path": "bill_of_lading.pdf",
"type": "bill-of-lading"
},
"labels": {
"lading_number": "s00158002",
"point_of_loading": "Chicago, United States",
"place_of_delivery": "Sydney, Australia",
"date": "2015-06-23",
"carrier": "Lucid Logistics",
"weight": "20000"
}
}{% endtab %} {% endtabs %}