diff --git a/get-started/preprocessing/other-setup-parameters.md b/get-started/preprocessing/other-setup-parameters.md
index 4c49778..c4d1c93 100644
--- a/get-started/preprocessing/other-setup-parameters.md
+++ b/get-started/preprocessing/other-setup-parameters.md
@@ -17,12 +17,12 @@ There are only two non-optional parameters in the setup function.
### Experiment Logging
-PyCaret can automatically log entire experiments including setup parameters, model hyperparameters, performance metrics, and pipeline artifacts. The default settings use [MLflow](https://mlflow.org/) as the logging backend. [wandb](https://wandb.ai/) is also available as an option for logging backend. A parameter in the setup can be enabled to automatically track all the metrics, hyperparameters, and other important information about your machine learning model.
+PyCaret can automatically log entire experiments including setup parameters, model hyperparameters, performance metrics, and pipeline artifacts. The default settings use [MLflow](https://mlflow.org/) as the logging backend. [wandb](https://wandb.ai/) and [dagshub](https://dagshub.com/) is also available as an option for logging backend. A parameter in the setup can be enabled to automatically track all the metrics, hyperparameters, and other important information about your machine learning model.
#### PARAMETERS
-* **log\_experiment: bool, default = bool or string 'mlflow' or 'wandb'**\
- A (list of) PyCaret `BaseLogger` or str (one of `mlflow`, `wandb`) corresponding to a logger to determine which experiment loggers to use. Setting to True will use the MLFlow backend by default.
+* **log\_experiment: bool, default = bool or string 'mlflow', 'wandb' or 'dagshub'**\
+ A (list of) PyCaret `BaseLogger` or str (one of `mlflow`, `wandb`, `dagshub`) corresponding to a logger to determine which experiment loggers to use. Setting to True will use the MLFlow backend by default.
* **experiment\_name: str, default = None**\
Name of the experiment for logging. When set to `None`, a default name is used.
* **experiment\_custom\_tags: dict, default = None**\
diff --git a/learn-pycaret/official-blog/bitcoin-price-forecasting-using-pycaret-with-dagshub.md b/learn-pycaret/official-blog/bitcoin-price-forecasting-using-pycaret-with-dagshub.md
new file mode 100644
index 0000000..ee99200
--- /dev/null
+++ b/learn-pycaret/official-blog/bitcoin-price-forecasting-using-pycaret-with-dagshub.md
@@ -0,0 +1,184 @@
+# How to use DagsHub with PyCaret
+Our new [integration with PyCaret](https://dagshub.com/blog/pycaret-integration/) is making waves in the data science community, and it's only been out for a week! The integration allows Pycaret users to log metrics, parameters, and data to DagsHub's remote servers using [MLflow](https://dagshub.com/docs/integration_guide/mlflow_tracking/), [DVC](https://dagshub.com/docs/integration_guide/dvc/), and DDA. This enables users to share experiments with teammates, make data-driven discussions, and reproduce results with a click of a button.
+
+In this blog, we'll cover how to use DagsHub Logger with PyCaret and log experiment to DagsHub. We will use the stock forecasting example with PyCaret's time series forecasting module.
+
+# What is the workflow of PyCaret and DagsHub?
+
+To use the DagsHub Logger with PyCaret, you only need to set the `log_experiment` parameter to `dagshub` when initializing your PyCaret experiment. For example:
+
+```python
+from pycaret.datasets import get_data
+from pycaret.regression import *
+
+data = get_data('diamond')
+
+s = setup(data,
+ target = 'Price',
+ transform_target=True,
+ log_experiment="dagshub",
+ experiment_name='predict_price',
+ log_data=True)
+```
+
+If the DagsHub Logger is not already authenticated on your local machine, the terminal will prompt you to enter the `repo_owner/repo_name` and provide an authentication link. Then the repository and remote MLflow server will be initialized in the background and configured with the local machine. From now, all the experiments you run with PyCaret will be logged with MLflow to DagsHub! Moreover, if you mark `log_data=True`, DagsHub Logger will also version the raw and processed data with DVC & DDA and push it to DagsHub.
+
+# Time Series Forecasting with PyCaret and DagsHub
+
+In this section, we'll get familiar with PyCaret's workflow and how to use it with DagsHub Logger. For that, we'll use the time series forecasting module on the stock datasets.
+
+
+
+## Library installation
+As PyCaret doesn't come with the dependency of DagsHub Client and MLflow, we need to install it for the project.
+
+```bash
+pip install --pre pycaret
+pip install dagshub
+pip install mlflow
+```
+
+The stock data comes from the `yfinance` library. Yfinance offers a threaded and Pythonic way to download market data from Yahoo! finance. We will use `BTC-USD` as an example. The model we’re using for this example is the `prophet`, one of the SOTA time-series models from Meta. Note that both `yfinance` and `prophet` should also be pre-installed:
+```bash
+pip install yfinance
+pip install prophet
+```
+## Get Stock data from yfinance
+Users can choose any kind of stock (ex. BTC-USD, ETH-USD) as long as they are supported by Yahoo! finance. The end date represents the last date of the data and the period is the duration between the start date and the end date. The interval defines the sampling frequency of the data.
+
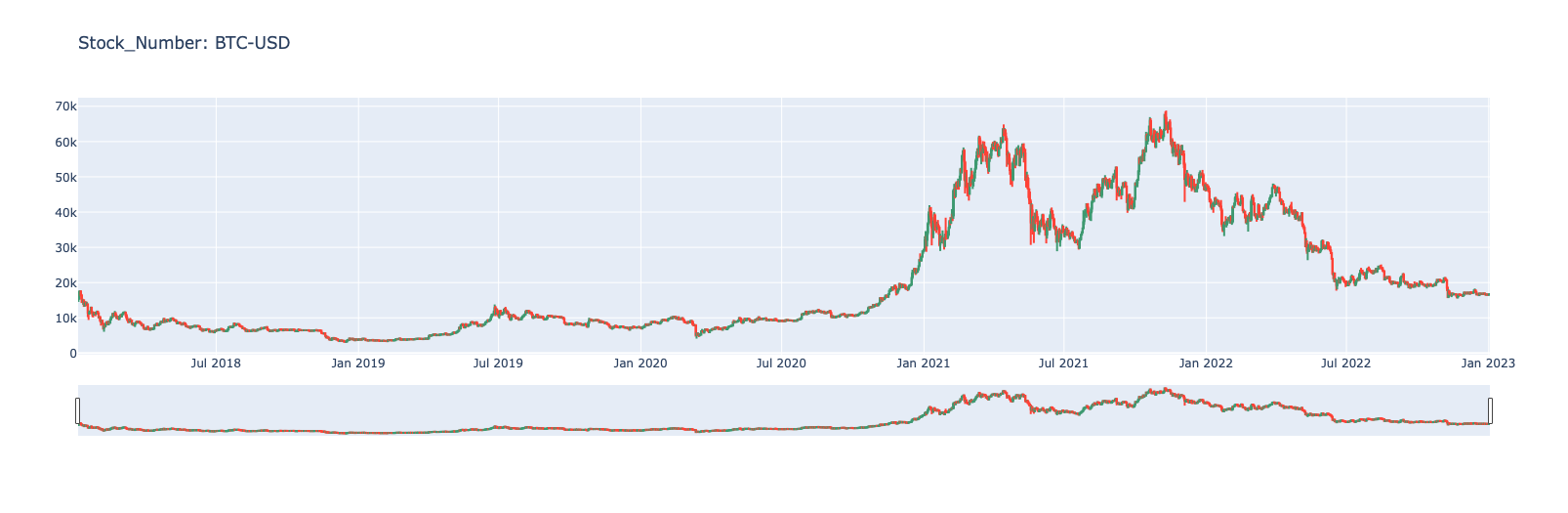
+## EDA with Plotly
+We use plotly, an interactive plot library, for data visualization. The interactive candlestick chart provides the open, closed, high, and low prices. With the cursor hovering on the specific date you want to take a look at, an annotation box will pop out with the stock information on that date.
+
+```python
+import plotly.graph_objects as go
+fig = go.Figure(data=[go.Candlestick(x=data['Date'],
+ open=data['Open'],
+ high=data['High'],
+ low=data['Low'],
+ close=data['Close'])])
+
+fig.update_layout(title_text=f"Stock_Number: {Stock_Number}")
+fig.show()
+```
+
+
+
+ Stock price over time
+
+
+## Setup DagsHub Logger with PyCaret
+We authorize PyCaret to log into DagsHub by setting `log_experiment=”dagshub”`.
+
+```python
+from pycaret.time_series import *
+
+ts = TSForecastingExperiment()
+ts.setup(
+ data=train,
+ target=target,
+ fh=ROLLING_WINDOW,
+ fold=FOLD,
+ enforce_exogenous=False,
+ numeric_imputation_target="ffill",
+ session_id=31,
+ log_experiment='dagshub',
+ log_data=True,
+ experiment_name="stock_forcast"
+ )
+```
+
+### Authentication
+As we run the setup, the terminal will pop out `go to ` for authentication. Follow the link and click on accept to get permission for all DagsHub API access to your account.
+
+Set up DagsHub repo
+
+As we finish the authorization process, the terminal will pop out a prompt asking for the repo owner and repo name:
+
+### Set up DagsHub repo
+As we finish the authorization process, the terminal will pop out a prompt asking for the repo owner and repo name:
+
+`Please insert your repository owner_name/repo_name:`
+
+**Note**: DagsHub will automatically create a repository if the repo doesn't exist.
+
+If `log_data=True`, the DagsHub logger will version and push the train/test data to the remote repository through DagsHub’s direct data access (DDA) feature, and version the data with DVC. The data will be uploaded to your remote repository's `artifacts/data/raw `directory.
+
+If transform_target=True, the target column will be transformed, and the new dataset will be pushed to the `artifacts/data/processed` in your remote repository.
+
+
+
+ Versioned data
+
+
+## Train a ML Model with PyCaret and DagsHub
+
+We create a prophet model by setting the estimator to `“prophet"`. To compare with different methods, a simple function call `compare_model()` will do the job, but we’re not going to dive into this part.
+
+```python
+best = ts.create_model("prophet")
+```
+
+### **Fine-tune the model**
+To find the best hyper-parameters, PyCaret also provided a simple way to do it. We use **mean absolute percentage error** (MAPE) and 5-fold cross-validation to optimize the model.
+
+```python
+tuned_model = ts.tune_model(estimator=best,
+ fold=5,
+ optimize="MAPE",
+ choose_better=True,
+ verbose=False)
+```
+
+`finalize_model()` will train the model with the best hyper-parameters using the entire dataset without splitting into train/validation
+
+```python
+final = ts.finalize_model(tuned_model)
+```
+
+## Model versioning with DagsHub:
+When calling `save_model()`, dagshub_logger will push the model to the remote repository through DagsHub’s direct data access (DDA) feature, and version the model with DVC. The model will be uploaded to the `artifacts/models` in your remote repository.
+
+```python
+ts.save_model(final, "prophet_tuned_best")
+```
+
+
+
+ Trained model versioned on DagsHub
+
+
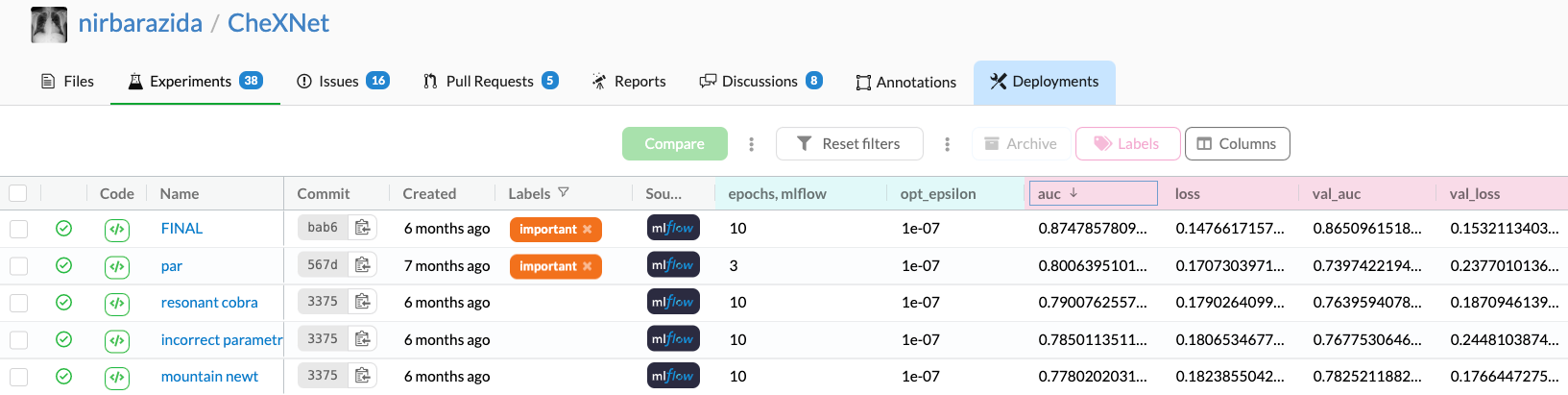
+## Experiment comparison with DagsHub
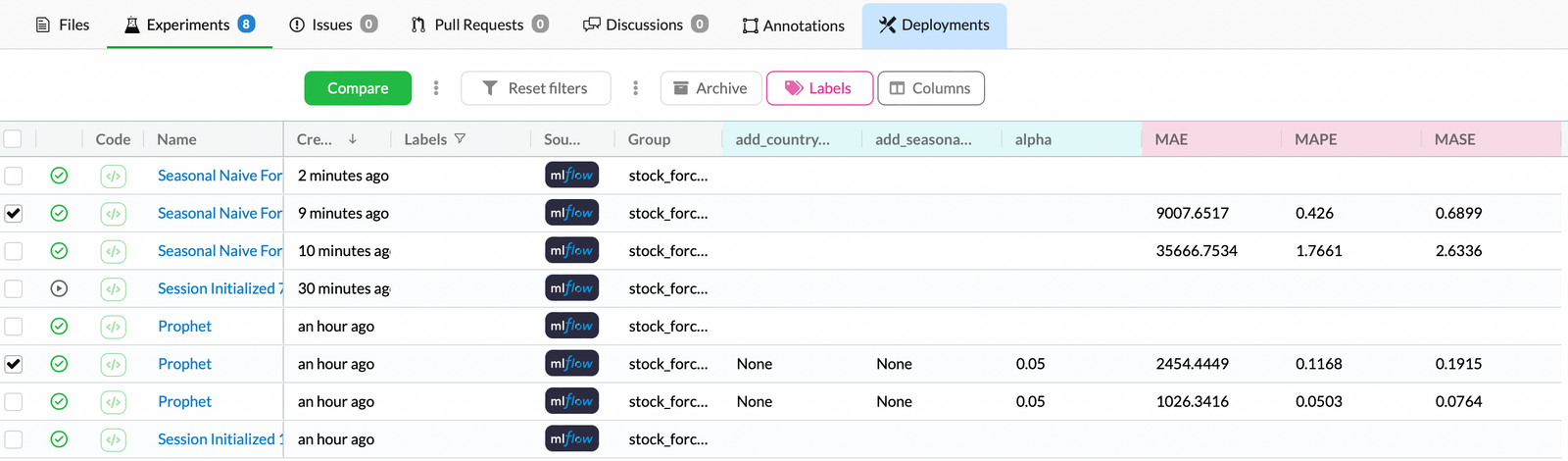
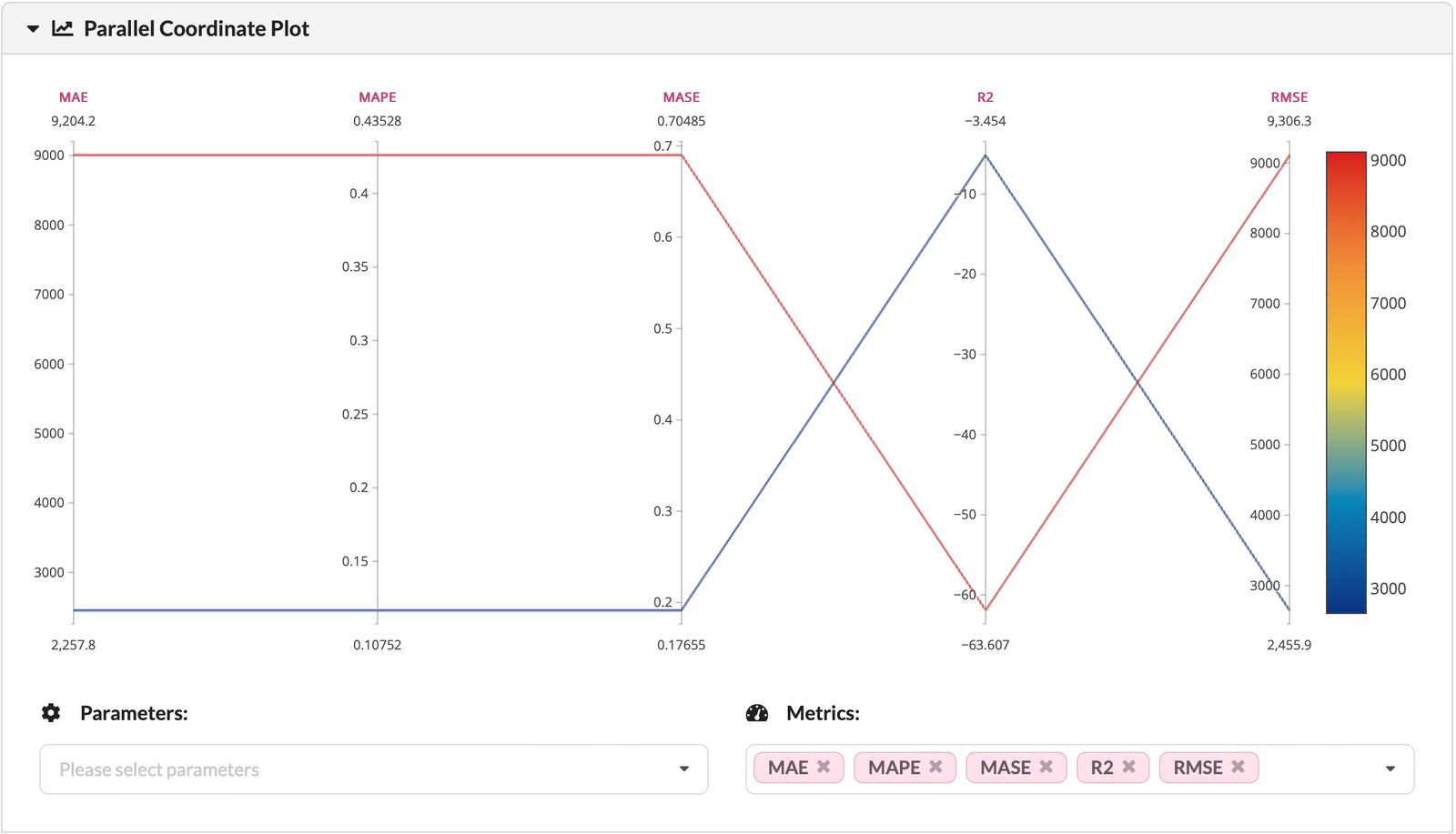
+Go to our DagsHub repository and click on the [experiment tab](https://dagshub.com/docs/feature_guide/discovering_experiments/). We are able to compare forecasting performance with different algorithms and setups. Moreover, we can choose the experiments we want to compare by clicking the check box and the green compare button. The hyper-parameters and the metrics will be compared using a table, parallel coordinate plot, and bar chart.
+
+
+
+ DagsHub's experiment table
+
+
+
+
+ DagsHub's parallel coordinate plot
+
+
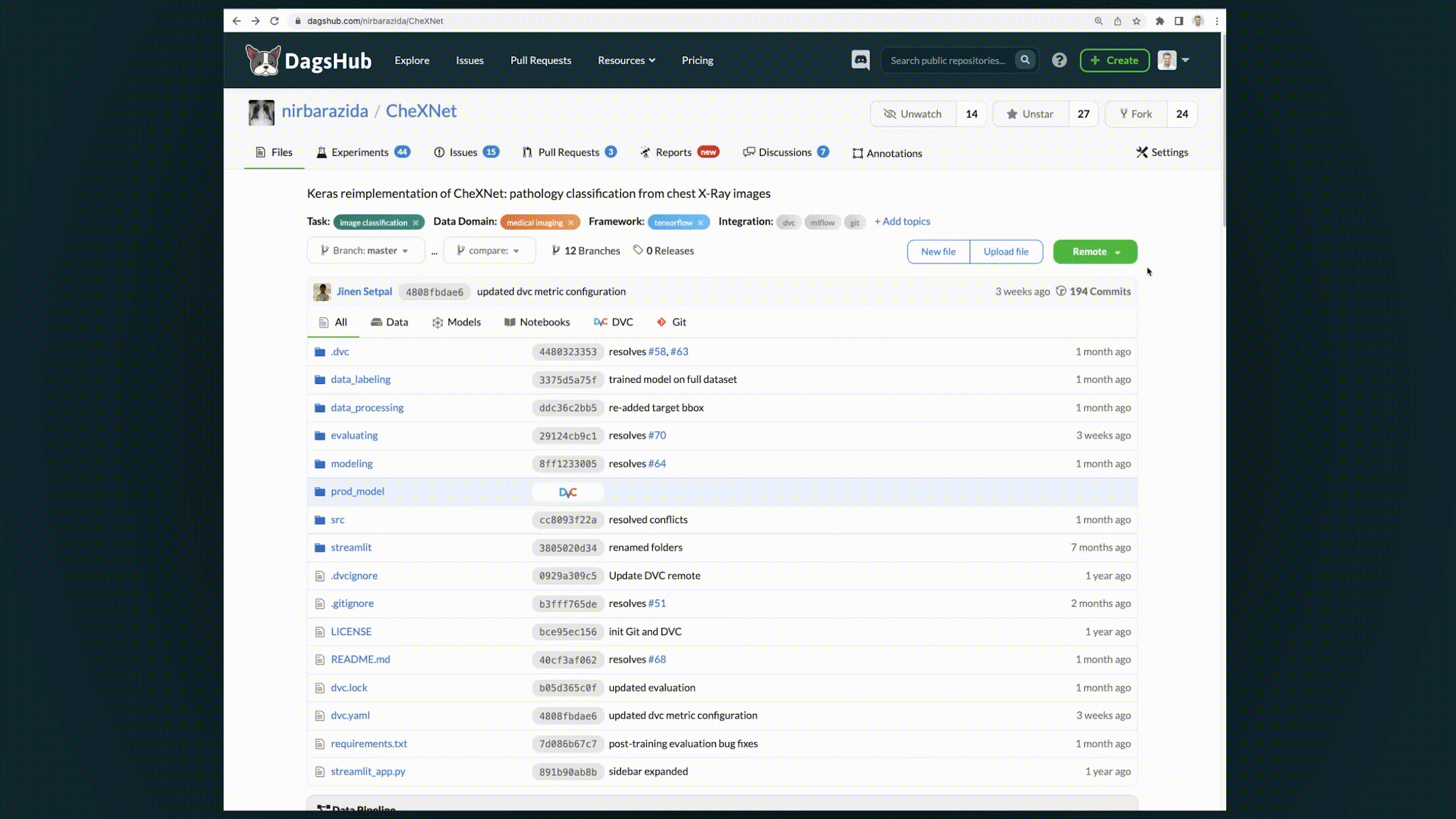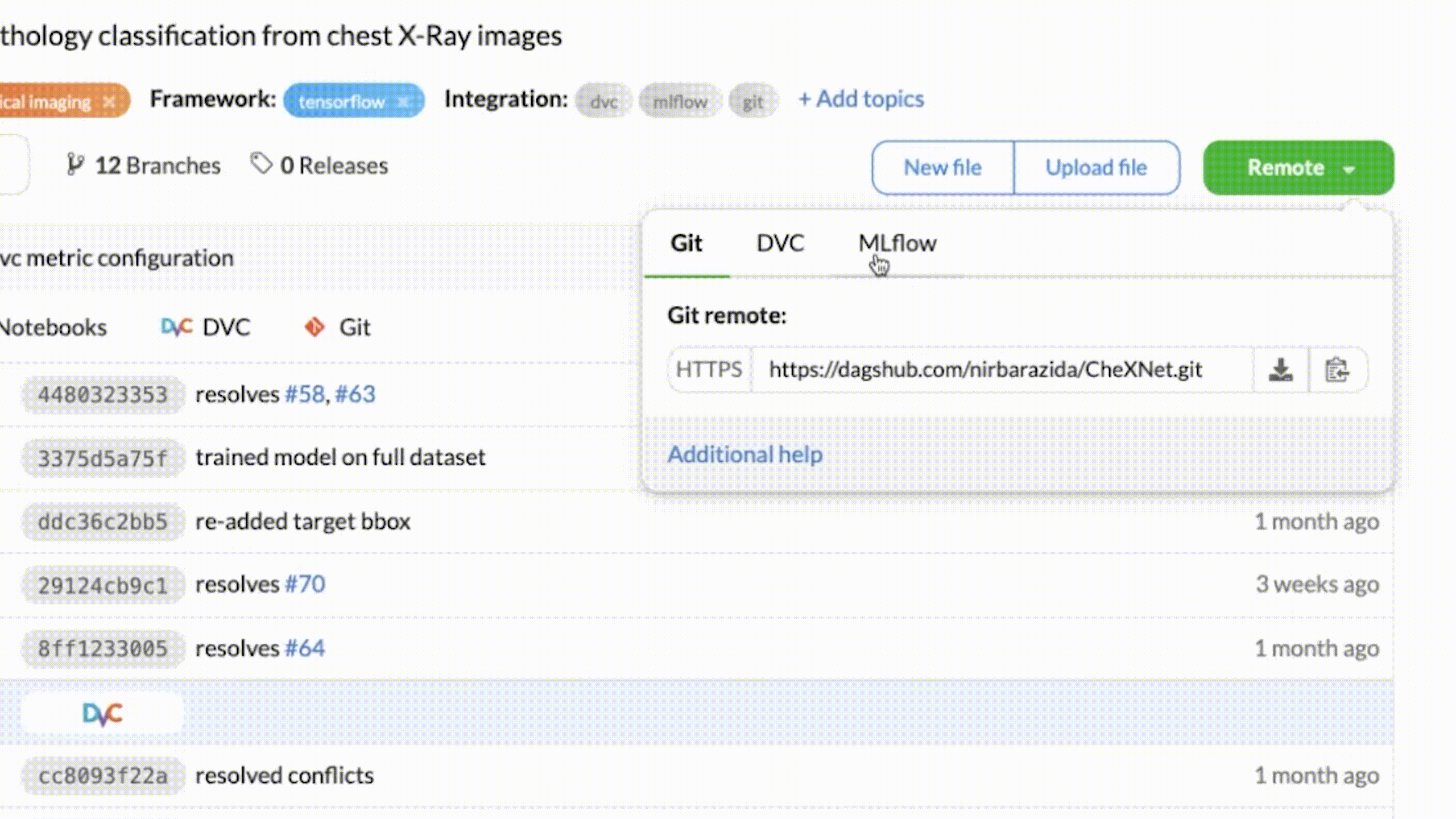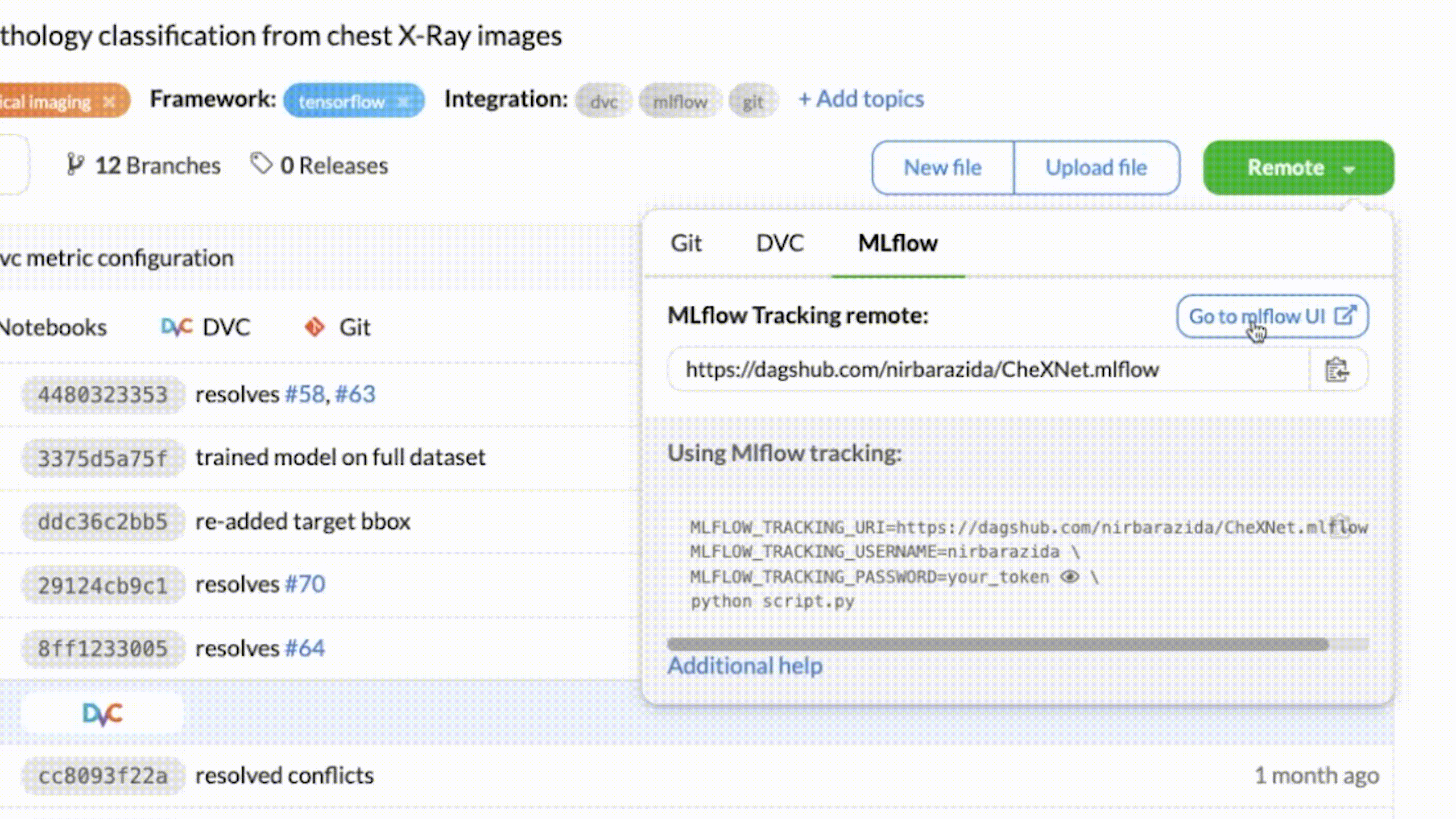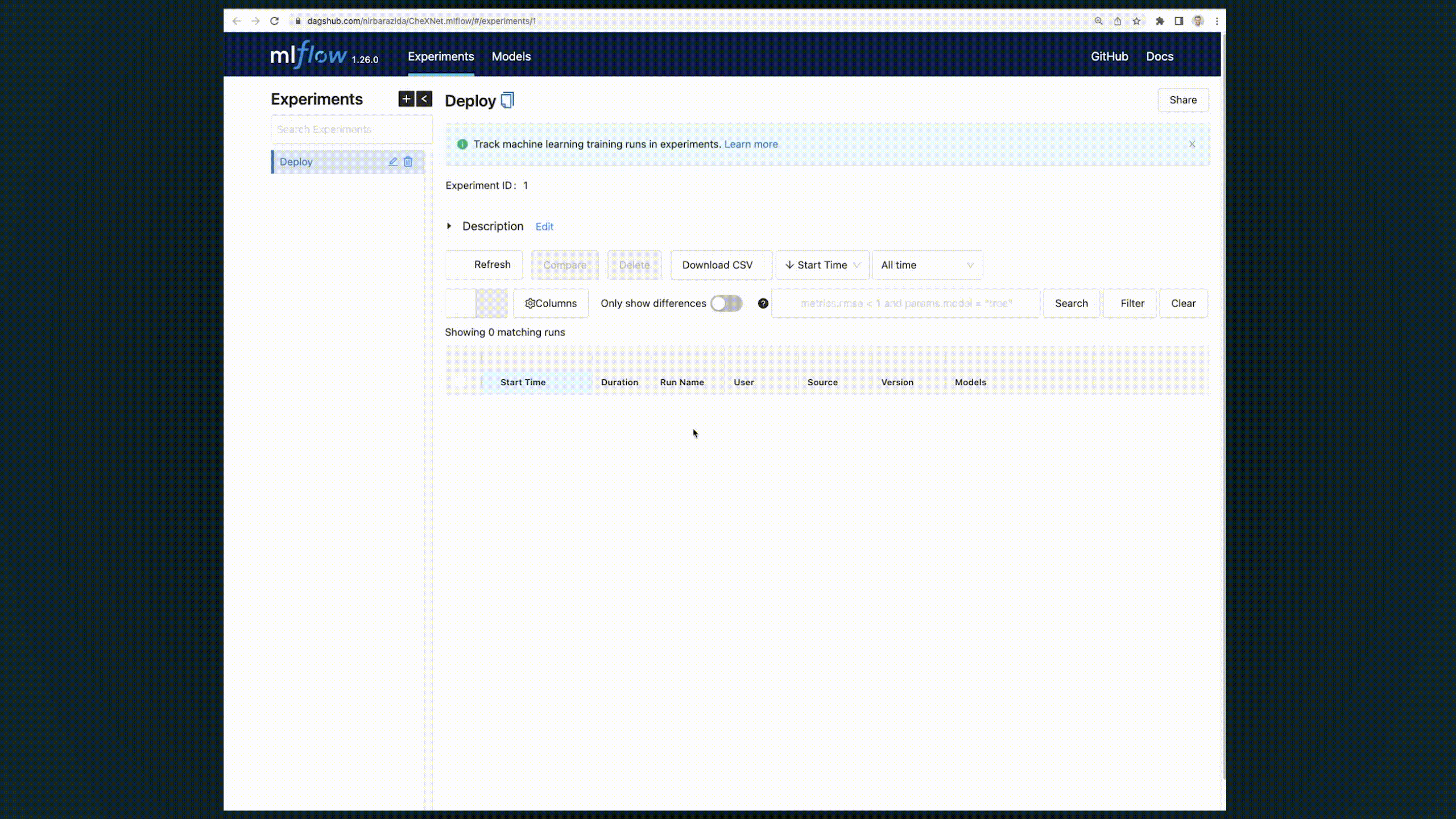
+## DagsHub's MLflow Fully Fledged UI
+If you want to use [MLflow's UI](https://dagshub.com/docs/integration_guide/mlflow_tracking/#how-to-launch-the-dagshub-mlflow-ui) - DagsHub provides it as well!
+
+
+
+
+
+Go to `https://dagshub.com//.mlflow` and see the wonder.
+
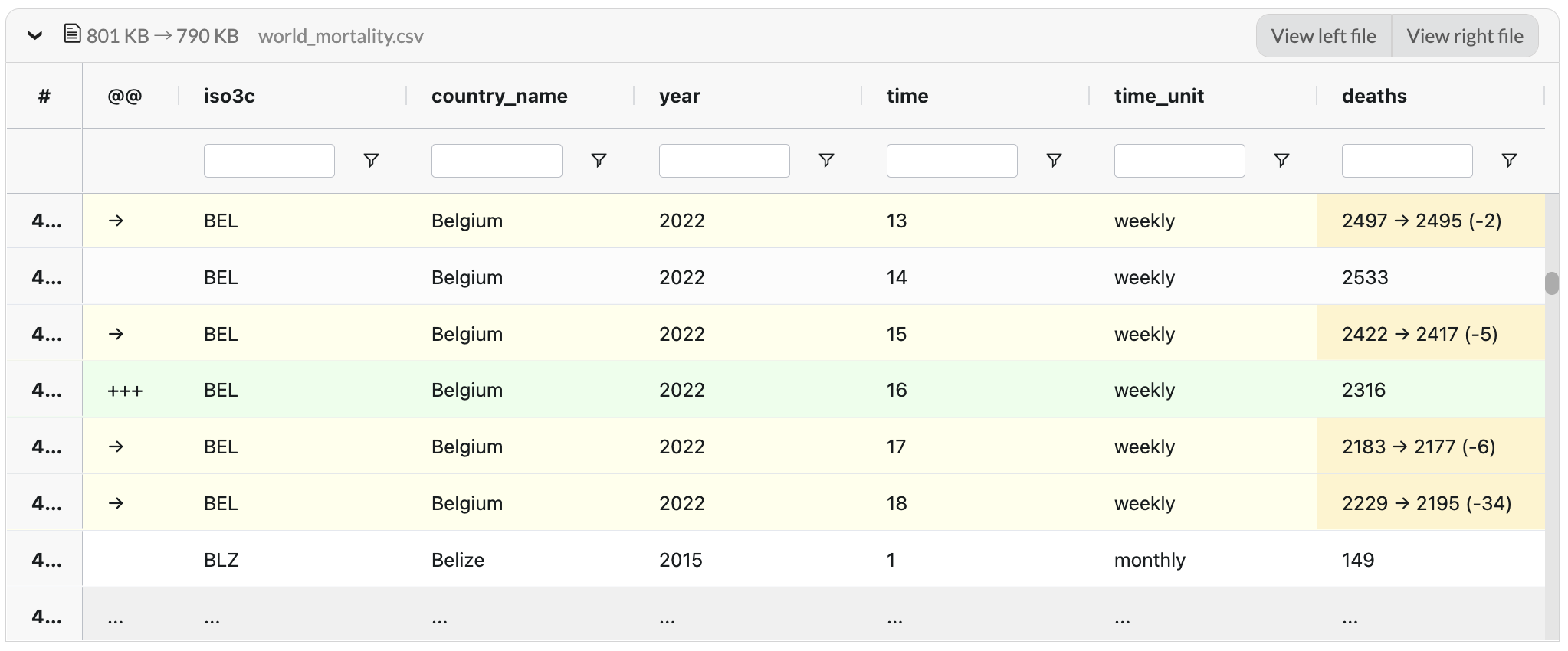
+## Data Diff with DagsHub
+If we have two experiment runs with the different time intervals of train.csv, such as `2017-12-16 ~ 2022-10-15` and `2018-01-07 ~ 2022-11-06`, we can diff the train.csv to check the table difference with DagsHub.
+
+
+
+
+
+## Conclusion
+The integration of PyCaret and DagsHub has made it possible for users to log their experiments, version data and work together on machine learning projects with ease. By using the DagsHub Logger, you can improve your machine learning workflow with PyCaret. We encourage you to share your experience with us on our community Discord and if you have any suggestions for enhancements, we would be happy to hear them and continue to improve this integration by adding more capabilities.
\ No newline at end of file
diff --git a/learn-pycaret/official-blog/mlops-with-pycaret-and-dagshub.md b/learn-pycaret/official-blog/mlops-with-pycaret-and-dagshub.md
new file mode 100644
index 0000000..4043d32
--- /dev/null
+++ b/learn-pycaret/official-blog/mlops-with-pycaret-and-dagshub.md
@@ -0,0 +1,80 @@
+# DagsHub's Integration with PyCaret
+With the latest integration between PyCaret and DagsHub, you can log your experiments and artifacts to DagsHub remote servers without making any changes to your code. This includes versioning raw and processed data with DVC and DDA, as well as logging experiment metrics, parameters, and trained models with MLflow. This integration allows you to continue using the familiar MLflow interface while also enabling you to collaborate with others, compare the results of different runs, and make data-driven decisions with ease.
+
+
To use the integration install pycaret==3.0.0.rc7 and above
+
+## What is PyCaret?
+
+PyCaret is an open-source, low-code machine learning library in Python that simplifies the process of training and deploying machine learning models. It offers a wide range of functions and features that make it easy to go from preparing your data to deploying your model within seconds.
+
+
+
+ PyCaret Pilers, from the office PyCaret website
+
+
+One of the main advantages of PyCaret is its end-to-end pipeline, which allows you to handle all aspects of your machine learning project within a single, integrated framework. This includes tasks such as data visualization, feature selection, model selection, and model training and deployment. In addition, PyCaret is designed to be low-code, meaning that you can accomplish a lot with just a few lines of code. This makes it accessible to users who may not have extensive coding experience.
+
+## What does the integration between DagsHub and PyCaret include?
+
+PyCaret provides an out-of-the-box integration with MLflow, enabling users to log important metrics, data, and plots on their local machines. This helps to organize the research phase and manage the projects as we move to production. However, it lacks the ability to collaborate with teammates and share results without moving to 3rd party platform (e.g., sending screenshots on Slack). Also, when logging data there is no easy way to see how different processing methods affected the data to make qualitative decisions.
+
+**This is where DagsHub comes into play.**
+
+DagsHub provides a remote MLflow server for each repository, enabling users to log experiments with MLflow and view and manage the results and trained models from the built-in UI. The DagsHUb repository also includes a fully configured object storage to store data, models, and any large file. Those files are diffable, enabling users to see the changes between different versions of their data and models, helping them to understand the impact of those changes on their results.
+
+
+
+ Data Diff on DagsHub
+
+
+With the new integration between PyCaret and DagsHub, you can now log experiments to your remote MLflow server hosted on DagsHub, diff experiments and share them with your friends and colleagues. On top of that, you can version your raw and processed data using DVC, push it to DagsHub to view, diff, and share them with others. All these are encapsulated under the new DagsHub Logger that is integrated into PyCaret. This means you need to change ONE line in your code and get all of these (and more) candies, without breaking any sweets.
+
+
+
+ Experiment Tracking with DagsHub
+
+
+## How to use DagsHub Logger with PyCaret?
+
+To use the DagsHub Logger with PyCaret, set the `log_experiment` parameter to `dagshub` when initializing your PyCaret experiment. For example:
+
+```python
+from pycaret.datasets import get_data
+from pycaret.regression import *
+
+data = get_data('diamond')
+
+s = setup(data,
+ target = 'Price',
+ transform_target=True,
+ log_experiment="dagshub",
+ experiment_name='predict_price',
+ log_data=True)
+```
+If the DagsHub Logger is not already authenticated on your local machine, the terminal will prompt you to enter the `repo_owner/repo_name` and provide an authentication link. The repository and remote MLflow server will then be automatically initialized in the background.
+
+## How to use DagsHub Logger programmatically?
+To avoid the authentication process, you can set two environment variables which will enable you to run your script programmatically.
+
+```bash
+os.environ["DAGSHUB_USER_TOKEN"] = ""
+os.environ['MLFLOW_TRACKING_URI'] = ""
+```
+
+The first environment variable will set up you’re DagsHub Token for our Client, which will be used for authentication and write access to the repo and remote. The second is you’re MLflow Tracking URI, hosted on DagsHub. We will use it to set up the remote configuration for the DagsHub Logger. Here is an example of such code:
+
+```python
+import os
+os.environ["DAGSHUB_USER_TOKEN"] = ""
+os.environ['MLFLOW_TRACKING_URI'] = "https://dagshub.com/nirbarazida/pycaret-test.mlflow"
+
+s = setup(data,
+ target = 'Price',
+ transform_target=True,
+ log_experiment="dagshub",
+ experiment_name='predict_price',
+ log_data=True)
+```
+
+## Conclusion
+The new integration between PyCaret and DagsHub makes it easy for you to log experiments, version data, and collaborate with others on machine learning projects. Give the DagsHub Logger a try and see how it can enhance your machine learning workflow with PyCaret. Let us know how it goes on our community [Discord](https://discord.com/invite/skXZZjJd2w) and if you have any enhancements requests - we’d love to enrich this integration and add more capabilities!
\ No newline at end of file
 +
+  +
+  +
+  +
+  +
+  +
+ +
+ +
+  +
+  +
+